Implementing PostgreSQL full-text search in Rails
A walkthrough
Jerad Gallinger <@jeradg>
Introduction
At Precision Nutrition, we recently launched an integrated search feature across some of our front-end applications. This feature provides a single search experience for users to be able to find content from across their courses, as well as curated links to resources from our blog, YouTube channel, and elsewhere.
For a first iteration of the integrated search, we wanted to get an MVP in our users’ hands quickly, at a low cost, and without adding devops work. Given that we use PostgreSQL as our primary data store, we decided to implement the initial version of the feature using PostgreSQL full-text search.
In this post, I’m going to walk you through implementing basic PostgreSQL full-text search in a Rails app. By the end, we’ll have a working GET /search endpoint with a user-friendly query syntax, highlighting of matched search terms, and sorting by search relevance. We’ll also set up database triggers to keep our search index up-to-date as source records are created, updated, and deleted.
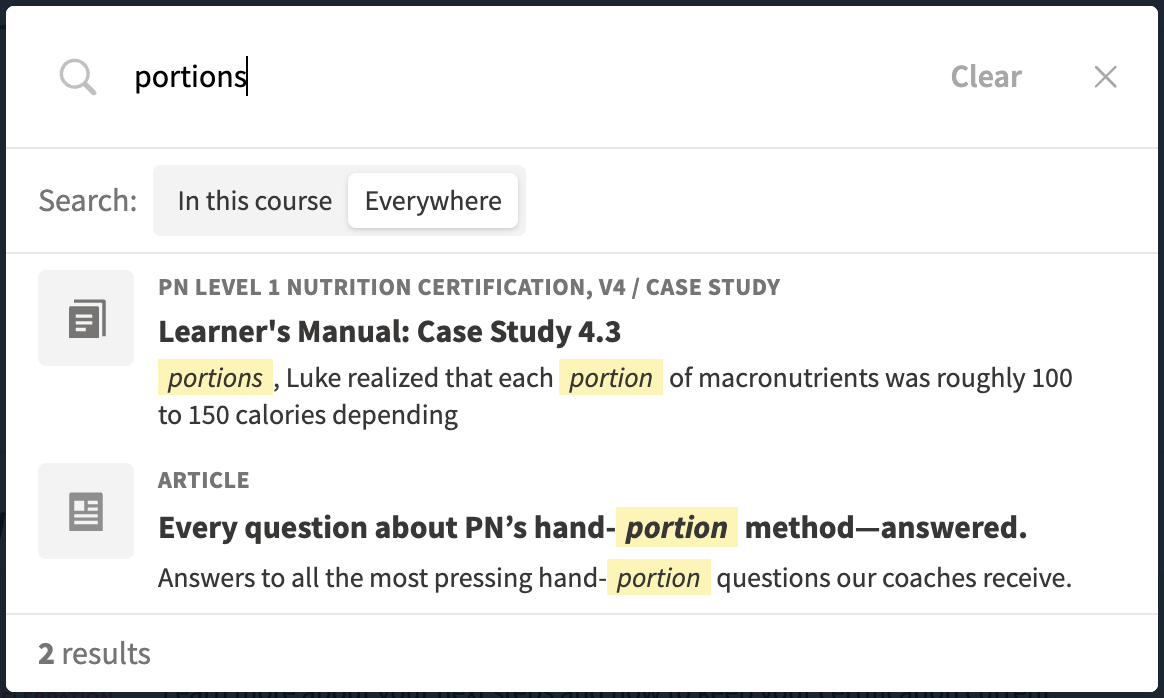
The walkthrough
Step 0: Setup
For the purposes of this walkthrough, let’s keep things simple. We have one model, **HelpfulLink**. In our app, helpful links are visible to everyone. They have three attributes we care about: title, description, and url.
Step 1: Create the SearchDoc model
While we only have one model for now, let’s imagine that we plan to add more in the near future: maybe user-specific Coupon records with URLs we’ll need to generate on the fly, Product listings, and more. We want our search feature to be able to return results for any record type we might come up with.
To provide a single search endpoint that returns links to URLs associated with different record types, let’s create a new record type, **SearchDoc**. Here’s the migration to create the search_docs table:
# db/migrate/20220211225723_create_search_docs.rb
class CreateSearchDocs < ActiveRecord::Migration[7.0]
def change
create_table :search_docs do |t|
t.tsvector :tsv, null: false, index: { using: :gin }
t.string :title, null: false
t.string :body, null: false
# this creates two columns, `searchable_id` and `searchable_type`
t.references :searchable, polymorphic: true, null: false
# We manually declare the timestamps here because we will be
# exclusively creating/updating search docs using postgres
# functions, and therefore will be skipping ActiveRecord
# callbacks that would otherwise populate the timestamp fields.
t.timestamp :created_at, null: false, default: -> { 'now()' }
t.timestamp :updated_at, null: false, default: -> { 'now()' }
t.index [:searchable_id, :searchable_type], unique: true
end
end
end
Let’s walk through the migration:
t.tsvector :tsv, null: false, index: { using: :gin }
This column, which we name tsv, is where we’ll store the processed text to search against, using the tsvector data type. Since we plan to search against this column frequently, we index it with the gin index type, which is the recommended index for tsvector columns.
t.string :title, null: false
t.string :body, null: false
We store the raw title and body fields in addition to the processed tsv so that we can render the highlighted title and body in the search results.
t.references :searchable, polymorphic: true, null: false
The searchable relationship is a reference to the source record. In the case of this example, we will use the search_docs.searchable_type and search_docs.searchable_id fields to join against the helpful_links table in order to return the url of the HelpfulLink in the API response.
t.timestamp :created_at, null: false, default: -> { 'now()' }
t.timestamp :updated_at, null: false, default: -> { 'now()' }
We manually declare the create_at and update_at timestamps here (rather than using the t.timestamps macro) because we will be using Postgres triggers, rather than ActiveRecord, to manage the lifecycle of SearchDoc records, meaning that ActiveRecord create and update lifecycle hooks that would otherwise populate the timestamp fields are never run.
The initial SearchDoc model is barebones, with only a reference to the searchable source record.
# app/models/search_doc.rb
class SearchDoc < ApplicationRecord
belongs_to :searchable, polymorphic: true
end
Step 2: rake task to add some SearchDocs for HelpfulLink records
After we’ve run the above migration, let’s create a rake task to seed SearchDoc entries for the existing HelpfulLink records in our database.
First, we’ll write a Postgres function to create a SearchDoc record based on a HelpfulLink. The function takes one argument, the ID of a source HelpfulLink, and upserts (creates or updates) a SearchDoc based on the source record.
/* app/sql/upsert_helpful_link_search_doc.sql */
CREATE OR REPLACE FUNCTION upsert_helpful_link_search_doc(helpful_link_to_reindex_id bigint) RETURNS void AS $$
BEGIN
INSERT INTO search_docs (searchable_id, searchable_type, title, body, tsv, updated_at)
SELECT
helpful_links.id searchable_id,
'HelpfulLink' searchable_type,
coalesce(helpful_links.title, '') title,
coalesce(helpful_links.description, '') body,
setweight(
to_tsvector(
'pg_catalog.english',
coalesce(helpful_links.title, '')
),
'A'
) ||
setweight(
to_tsvector(
'pg_catalog.english',
coalesce(helpful_links.description, '')
),
'D'
)
tsv,
now() updated_at
FROM helpful_links
WHERE id = helpful_link_to_reindex_id
ON CONFLICT (searchable_id, searchable_type)
DO UPDATE
SET title = excluded.title,
body = excluded.body,
tsv = excluded.tsv,
updated_at = excluded.updated_at;
END;
$$ LANGUAGE plpgsql;
With respect to full-text search, the key part is:
/* ... */
setweight(
to_tsvector(
'pg_catalog.english',
coalesce(helpful_links.title, '')
),
'A'
) ||
setweight(
to_tsvector(
'pg_catalog.english',
coalesce(helpful_links.description, '')
),
'D'
)
tsv,
/* ... */
Looking at this snippet from the inside out:
- We use the
coalescefunction on the raw text to provide a default value of''if the text isNULL. This ensures that the call toto_tsvectoralways returns atsvector, sinceto_tsvectorreturnsNULLif it is passed aNULLtext document. (You could argue that theNOT NULLconstraint on thetitleanddescriptioncolumns means this should never happen, but there isn’t really a downside to usingcoalescehere, so safety first!) - The
to_tsvectorfunction converts the coalesced source text into thetsvectordata type. - The
setweightfunction takes atsvectorand a character'A','B',‘C', or'D'(with'A'having the highest weight), and returns atsvectorwith weighted lexemes. - The two
tsvectorvalues (one fortitlewith a weight of'A', the other fordescriptionwith a weight of'D') are then merged together with the||operator, to create a singletsvectorvalue.- By merging the two
tsvectorvalues together instead of first merging the rawtitleanddescriptiontext values together, we are able to assign different weights to the two pieces of text, while still storing them in the single resultingtsvector.
- By merging the two
- The merged
tsvectoris assigned to thetsvfield of the newSearchDocrecord.
After writing the function, we need to add it to our database schema. We can do so with a migration:
# db/migrate/20220223221910_add_upsert_helpful_link_search_doc_function.rb
class AddUpsertHelpfulLinkSearchDocFunction < ActiveRecord::Migration[7.0]
def up
execute Rails.root.join('app/sql/upsert_helpful_link_search_doc.sql').read
end
def down
end
end
After running the migration, let’s create a rake task to backfill SearchDoc records for all of our existing HelpfulLinks:
# lib/tasks/backfill_search_docs.rake
namespace :search_docs do
desc 'index helpful links for search'
task index_helpful_links: :environment do
execute <<~SQL
SELECT upsert_helpful_link_search_doc(id) FROM helpful_links;
SQL
end
def execute(string)
ActiveRecord::Base.connection.execute(string)
end
end
Run the rake task…
$ rails search_docs:index_helpful_links
…then open the rails console and confirm that the correct SearchDoc records were created:
$ rails c
Loading development environment (Rails 7.0.2)
irb(main):001:0> SearchDoc.all
SearchDoc Load (1.5ms) SELECT "search_docs".* FROM "search_docs"
=>
[#<SearchDoc:0x00000001336e2a38
id: 1,
title: "Wikipedia: Cat food",
body: "Starting from first principles",
tsv: "'cat':2A 'first':6 'food':3A 'principl':7 'start':4 'wikipedia':1A",
searchable_type: "HelpfulLink",
searchable_id: 1,
created_at: Tue, 15 Mar 2022 20:55:13.611931000 UTC +00:00,
updated_at: Tue, 15 Mar 2022 20:55:13.611931000 UTC +00:00>,
#<SearchDoc:0x00000001364d7bc8
id: 2,
title: "Organic kitty treats",
body: "For fancy cats who are healthy too",
tsv: "'cat':6 'fanci':5 'healthi':9 'kitti':2A 'organ':1A 'treat':3A",
searchable_type: "HelpfulLink",
searchable_id: 2,
created_at: Tue, 15 Mar 2022 20:55:13.611931000 UTC +00:00,
updated_at: Tue, 15 Mar 2022 20:55:13.611931000 UTC +00:00>,
#<SearchDoc:0x00000001364d7a60
id: 3,
title: "Annex Cat Rescue",
body: "Find a fluffy friend to feed treats to",
tsv: "'annex':1A 'cat':2A 'feed':9 'find':4 'fluffi':6 'friend':7 'rescu':3A 'treat':10",
searchable_type: "HelpfulLink",
searchable_id: 3,
created_at: Tue, 15 Mar 2022 20:55:13.611931000 UTC +00:00,
updated_at: Tue, 15 Mar 2022 20:55:13.611931000 UTC +00:00>]
Nice.
Step 3: Implement the basic GET /search endpoint
Now that we have some search documents in the database, let’s create an API endpoint so that the user can search for helpful links. We’re going to add a GET /search endpoint that accepts a query query parameter and returns a JSON payload with an array of hits.
# app/models/search_doc.rb
class SearchDoc < ApplicationRecord
belongs_to :searchable, polymorphic: true
default_scope { select('search_docs.*') }
scope :query, lambda { |webquery|
joins(
sanitize_sql([
", websearch_to_tsquery('english', '%s') query",
webquery
])
)
.where('query @@ tsv')
}
end
# config/routes.rb
Rails.application.routes.draw do
get 'search', to: 'search#index'
end
# app/controllers/search_controller.rb
class SearchController < ApplicationController
def index
records = fetch_results
payload = { hits: serialize(records) }
render json: payload
end
private
def fetch_results
SearchDoc
.includes(:searchable)
.query(search_params[:query])
end
def search_params
params.permit(:query)
end
def serialize(results)
results.map { |result|
{
body: result.body,
searchable_id: result.searchable_id,
searchable_type: result.searchable_type,
title: result.title,
url: result.searchable.url,
}
}
end
end
There’s a lot going on here, especially in the SearchDoc model. Let’s walk through the trickiest bits.
default_scope { select('search_docs.*') }
We need to add this default scope because the select clauses added by other scopes override the implicit select search_docs.*.
scope :query, lambda { |webquery|
joins(
sanitize_sql([
", websearch_to_tsquery('english', '%s') query",
webquery
])
)
.where('query @@ tsv')
}
- The
websearch_to_tsqueryPostgres function takes a text query and returns atsqueryvalue. (tsqueryis a data type used to querytsvectordocuments.)websearch_to_tsquerysupports some basic search operators familiar to users of typical websearch interfaces. For example, text inside quotation marks like"quoted text"is treated as an exact phrase; and you can exclude a word by prefixing it with the-character, likecat treats -tuna. @@is the match operator. The expressionquery @@ tsvevaluates totrueif thetsvectordocument matches thetsqueryquery.
Let’s try out our new endpoint in the terminal. First, start a rails server in the terminal. Then in another terminal window, send a search request with curl (formatting the JSON response with jq):
$ curl -sS http://localhost:3000/search\?query\=treat | jq
{
"hits": [
{
"body": "For fancy cats who are healthy too",
"searchable_id": 2,
"searchable_type": "HelpfulLink",
"title": "Organic kitty treats",
"url": "https://duckduckgo.com/?q=organic+cat+treats"
},
{
"body": "Find a fluffy friend to feed treats to",
"searchable_id": 3,
"searchable_type": "HelpfulLink",
"title": "Annex Cat Rescue",
"url": "https://annexcatrescue.ca/"
}
]
}
Heck yeah, we have a working search endpoint!
Step 4: Add highlighting
Now that we have our search endpoint running, let’s give the user some context on why a given search result was returned in response to their query.
The ts_headline PostgreSQL function accepts some text and a tsquery and returns an excerpt from the document with terms from the query highlighted.
By default, “highlighted” means “wrapped in <b></b> tags”, which isn’t very useful these days. To get around this behaviour, we can pass optional StartSel and StopSel parameters to tell ts_headline what we would like to wrap the highlighted text in. For example, we can use StartSel=[HIGHLIGHT], StopSel=[/HIGHLIGHT] to have the highlights returned wrapped in [HIGHLIGHT][/HIGHLIGHT], which we can then parse on the front-end and turn into whatever HTML we want.
First we add a with_highlights scope to the model.
# app/models/search_doc.rb
class SearchDoc < ApplicationRecord
belongs_to :searchable, polymorphic: true
default_scope { select('search_docs.*') }
scope :with_highlights, lambda {
selection_options = 'StartSel = [HIGHLIGHT], StopSel = [/HIGHLIGHT]'
scope = select <<~SQL
ts_headline('english', search_docs.title, query, '#{selection_options}') highlighted_title,
ts_headline('english', left(search_docs.body, 2500), query, '#{selection_options}') highlighted_body
SQL
merge(scope)
}
scope :query, lambda { |webquery|
# ... same as before
}
end
(Note that we use left() to truncate the body to the first 2500 characters. ts_headline is an expensive function, so we want to avoid passing it large amounts of text. The tradeoff is that if the matching text doesn’t appear in the first 2500 characters of the body, it won’t show up in the highlighted text, which can be confusing to the user.)
Next, we use the with_highlights scope and the new highlighted_body and highlighted_title in the search controller.
# app/controllers/search_controller.rb
class SearchController < ApplicationController
def index
# ... same as before
end
private
def fetch_results
SearchDoc
.includes(:searchable)
.with_highlights
.query(search_params[:query])
end
def search_params
# ... same as before
end
def serialize(results)
results.map { |result|
{
body: result.highlighted_body,
searchable_id: result.searchable_id,
searchable_type: result.searchable_type,
title: result.highlighted_title,
url: result.searchable.url,
}
}
end
end
We now have highlighting in the search results:
$ curl -sS http://localhost:3000/search\?query\=treat | jq
{
"hits": [
{
"body": "For fancy cats who are healthy too",
"searchable_id": 2,
"searchable_type": "HelpfulLink",
"title": "Organic kitty [HIGHLIGHT]treats[/HIGHLIGHT]",
"url": "https://duckduckgo.com/?q=organic+cat+treats"
},
{
"body": "Find a fluffy friend to feed [HIGHLIGHT]treats[/HIGHLIGHT] to",
"searchable_id": 3,
"searchable_type": "HelpfulLink",
"title": "Annex Cat Rescue",
"url": "https://annexcatrescue.ca/"
}
]
}
Step 5: Add sorting by rank
With our search results highlighted, we’re very close to having a useful, basic search endpoint. The missing piece is to ensure that the most relevant search results are shown at the top of the list of search hits. Currently, if we search for cat -wikipedia (results that match cat, excluding results that match wikipedia), we get:
$ curl -sS http://localhost:3000/search\?query\=cat\%20-wikipedia | jq
{
"hits": [
{
"body": "For fancy [HIGHLIGHT]cats[/HIGHLIGHT] who are healthy too",
"searchable_id": 2,
"searchable_type": "HelpfulLink",
"title": "Organic kitty treats",
"url": "https://duckduckgo.com/?q=organic+cat+treats"
},
{
"body": "Find a fluffy friend to feed treats to",
"searchable_id": 3,
"searchable_type": "HelpfulLink",
"title": "Annex [HIGHLIGHT]Cat[/HIGHLIGHT] Rescue",
"url": "https://annexcatrescue.ca/"
}
]
}
However, based on the weights we set in the upsert_helpful_link_search_doc function, results with a match in the title are more relevant and should be displayed before those with a match in the body.
In order to sort our results taking this into account, we can calculate the rank of each search result and sort the results in descending order based on rank.
# app/models/search_doc.rb
class SearchDoc < ApplicationRecord
belongs_to :searchable, polymorphic: true
default_scope { select('search_docs.*') }
scope :with_rank, lambda {
merge(select('ts_rank_cd(search_docs.tsv, query, 32) as rank'))
}
# ... and the rest is the same as before
end
The ts_rank_cd function computes the cover density ranking for a tsvector document and a query. (The ts_rank function can also be used to calculate the rank of documents for a query, but it ignores the position and weight of the lexemes in the document.)
In the search controller, we can now use the with_rank scope, and order the search results in descending order by rank.
# app/controllers/search_controller.rb
class SearchController < ApplicationController
def index
# ...
end
private
def fetch_results
SearchDoc
.includes(:searchable)
.with_rank
.with_highlights
.query(search_params[:query])
.order({ rank: :desc })
end
# ...
end
The search results are now returned with the relative weighting of title and body taken into account.
$ curl -sS http://localhost:3000/search\?query\=cat\%20-wikipedia | jq
{
"hits": [
{
"body": "Find a fluffy friend to feed treats to",
"searchable_id": 3,
"searchable_type": "HelpfulLink",
"title": "Annex [HIGHLIGHT]Cat[/HIGHLIGHT] Rescue",
"url": "https://annexcatrescue.ca/"
},
{
"body": "For fancy [HIGHLIGHT]cats[/HIGHLIGHT] who are healthy too",
"searchable_id": 2,
"searchable_type": "HelpfulLink",
"title": "Organic kitty treats",
"url": "https://duckduckgo.com/?q=organic+cat+treats"
}
]
}
Step 6: Add a SQL trigger to create/update/delete SearchDoc records when HelpfulLink records change
As a finishing touch, let’s add a database trigger to ensure that new SearchDoc records are created when HelpfulLink records are added to the database, and that any changes to an existing HelpfulLink record are reflected in its associated SearchDoc.
Fortunately, we did all the hard work when we wrote the upsert_helpful_link_search_doc function. We can use it in a trigger, along with a trigger to delete SearchDoc records when HelpfulLink records are deleted.
/* app/sql/helpful_link_search_doc_triggers.sql */
CREATE OR REPLACE FUNCTION upsert_helpful_link_search_doc_on_change() RETURNS TRIGGER AS $$
BEGIN
perform upsert_helpful_link_search_doc(new.id);
RETURN NULL;
END;
$$ language plpgsql;
CREATE OR REPLACE FUNCTION delete_helpful_link_search_doc_on_delete() RETURNS TRIGGER AS $$
BEGIN
DELETE FROM search_docs WHERE searchable_id = old.id AND searchable_type = 'HelpfulLink';
RETURN NULL;
END;
$$ language plpgsql;
DROP TRIGGER IF EXISTS upsert_helpful_link_search_doc_on_change ON helpful_links;
CREATE TRIGGER upsert_helpful_link_search_doc_on_change AFTER INSERT OR UPDATE ON helpful_links
FOR EACH ROW EXECUTE PROCEDURE upsert_helpful_link_search_doc_on_change();
DROP TRIGGER IF EXISTS delete_helpful_link_search_doc_on_delete ON helpful_links;
CREATE TRIGGER delete_helpful_link_search_doc_on_delete AFTER DELETE ON helpful_links
FOR EACH ROW EXECUTE PROCEDURE delete_helpful_link_search_doc_on_delete();
Now we create a migration to install the triggers:
# db/migrate/20220316214532_install_helpful_link_search_doc_triggers.rb
class InstallHelpfulLinkSearchDocTriggers < ActiveRecord::Migration[7.0]
def up
execute Rails.root.join('app/sql/helpful_link_search_doc_triggers.sql').read
end
def down
end
end
Run the migration and confirm everything works as expected.
$ rails db:migrate
== 20220316214532 InstallHelpfulLinkSearchDocTriggers: migrating ==============
== 20220316214532 InstallHelpfulLinkSearchDocTriggers: migrated (0.0051s) =====
Finally, we’ll verify that the triggers are working. First we create a new HelpfulLink and check that the SearchDoc is there as expected.
$ rails c
Loading development environment (Rails 7.0.2)
irb(main):001:1* helpful_link = HelpfulLink.create(
irb(main):002:1* title: 'Treat yourself and your fluffy friend',
irb(main):003:1* description: 'Cozy blankets for humans and felines alike',
irb(main):004:1* url: 'https://cat-blankets.example.com'
irb(main):005:0> )
TRANSACTION (0.1ms) BEGIN
HelpfulLink Create (5.0ms) INSERT INTO "helpful_links" ("title", "description", "url", "created_at", "updated_at") VALUES ($1, $2, $3, $4, $5) RETURNING "id" [["title", "Treat yourself and your fluffy friend"], ["description", "Cozy blankets for humans and felines alike"], ["url", "https://cat-blankets.example.com"], ["created_at", "2022-03-16 22:03:20.319339"], ["updated_at", "2022-03-16 22:03:20.319339"]]
TRANSACTION (1.6ms) COMMIT
=>
#<HelpfulLink:0x000000010804c2f8
id: 4,
title: "Treat yourself and your fluffy friend",
description: "Cozy blankets for humans and felines alike",
url: "https://cat-blankets.example.com",
created_at: Wed, 16 Mar 2022 22:03:20.319339000 UTC +00:00,
updated_at: Wed, 16 Mar 2022 22:03:20.319339000 UTC +00:00>
irb(main):006:0> search_doc = SearchDoc.find_by(searchable_id: helpful_link.id, searchable_type: 'HelpfulLink')
SearchDoc Load (1.8ms) SELECT search_docs.* FROM "search_docs" ORDER BY "search_docs"."id" DESC LIMIT $1 [["LIMIT", 1]]
=>
#<SearchDoc:0x000000011a6c8458
id: 4,
title: "Treat yourself and your fluffy friend",
body: "Cozy blankets for humans and felines alike",
tsv: "'alik':13 'blanket':8 'cozi':7 'felin':12 'fluffi':5A 'friend':6A 'human':10 'treat':1A",
searchable_type: "HelpfulLink",
searchable_id: 4,
created_at: Wed, 16 Mar 2022 22:03:20.319728000 UTC +00:00,
updated_at: Wed, 16 Mar 2022 22:03:20.319728000 UTC +00:00>
Looks good! Let’s update the HelpfulLink and make sure its SearchDoc changes too.
irb(main):007:0> HelpfulLink.last.update(title: 'Cat blankets are the hot new trend')
HelpfulLink Load (0.3ms) SELECT "helpful_links".* FROM "helpful_links" ORDER BY "helpful_links"."id" DESC LIMIT $1 [["LIMIT", 1]]
TRANSACTION (0.1ms) BEGIN
HelpfulLink Update (0.5ms) UPDATE "helpful_links" SET "title" = $1, "updated_at" = $2 WHERE "helpful_links"."id" = $3 [["title", "Cat blankets are the hot new trend"], ["updated_at", "2022-03-16 22:05:54.071998"], ["id", 4]]
TRANSACTION (0.7ms) COMMIT
=> true
irb(main):008:0> search_doc.reload
SearchDoc Load (1.2ms) SELECT search_docs.* FROM "search_docs" WHERE "search_docs"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]]
=>
#<SearchDoc:0x000000011a1add38
id: 4,
title: "Cat blankets are the hot new trend",
body: "Cozy blankets for humans and felines alike",
tsv: "'alik':14 'blanket':2A,9 'cat':1A 'cozi':8 'felin':13 'hot':5A 'human':11 'new':6A 'trend':7A",
searchable_type: "HelpfulLink",
searchable_id: 4,
created_at: Wed, 16 Mar 2022 22:03:20.319728000 UTC +00:00,
updated_at: Wed, 16 Mar 2022 22:03:20.319728000 UTC +00:00>
And to top it all off, let’s destroy the HelpfulLink and confirm that the SearchDoc is destroyed along with it.
irb(main):009:0> HelpfulLink.last.destroy!
HelpfulLink Load (0.9ms) SELECT "helpful_links".* FROM "helpful_links" ORDER BY "helpful_links"."id" DESC LIMIT $1 [["LIMIT", 1]]
TRANSACTION (0.2ms) BEGIN
HelpfulLink Destroy (1.3ms) DELETE FROM "helpful_links" WHERE "helpful_links"."id" = $1 [["id", 4]]
TRANSACTION (0.9ms) COMMIT
=>
#<HelpfulLink:0x000000011a34f970
id: 4,
title: "Cat blankets are the hot new trend",
description: "Cozy blankets for humans and felines alike",
url: "https://cat-blankets.example.com",
created_at: Wed, 16 Mar 2022 22:03:20.319339000 UTC +00:00,
updated_at: Wed, 16 Mar 2022 22:05:54.071998000 UTC +00:00>
irb(main):010:0> search_doc.reload
SearchDoc Load (1.1ms) SELECT search_docs.* FROM "search_docs" WHERE "search_docs"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]]
Traceback (most recent call last):
/usr/local/var/rbenv/versions/2.7.5/lib/ruby/gems/2.7.0/gems/activerecord-7.0.2/lib/active_record/relation/finder_methods.rb:381:in `raise_record_not_found_exception!':
Couldn't find SearchDoc with 'id'=4 (ActiveRecord::RecordNotFound)
Good stuff! Our triggers all work as expected.
Conclusion
We’ve just scratched the surface of PostgreSQL full-text search in the context of a Rails app, but we already have a useful feature for our users. I hope you’ve enjoyed this whirlwind tour!
To find out more about the features discussed in this post, you can dig into the official documentation for PostgreSQL full-text search.
A huge thanks to colleagues Justin Giancola and Christopher Milne, my fellow devs on the integrated search feature that inspired this post.